
Natural language processing (NLP) is a set of techniques that aim to interpret and analyze human languages. By using it in more complex pipelines, we can solve predictive analytics tasks and extract valuable insights from unstructured text data.
A major breakthrough was made in the field of NLP by the introduction of transformers, which paved the way for large language models (LLMs) and generative AI research (e.g. BERT, BART, GPT).
In this article, we walk through different concepts of NLP. In the first section, we summarize the architecture of transformers and highlight its core concepts, such as the attention mechanism. Then, in the second section, we focus on BERT, one of the most popular Transformer-based LLMs, and we present examples of how it is used in data science applications.
Understanding the transformer architecture
A Transformer, originally proposed in the paper attention is all you need [1], is an encoder-decoder-based neural network that is mainly characterized by the use of the attention mechanism to capture long-range dependencies in sequential data.
Attention mechanism learns the importance scores of each word to other words in the same sentence (self-attention) or between words from the input and target sentences (encoder-decoder attention).
This alleviates the need to use recurrent connections to model sequences, as in recurrent neural networks (RNNs) [2], which preclude the parallelization of the training process. As such, in transformers, the input sequence can be passed in parallel (e.g. all words can be passed simultaneously). This makes them significantly faster to train. Note that to encode information about the order of words in a sequence, as in RNNs, transformers use positional encoding blocks.
Architecture
The original transformer architecture is as follows (cf. Figure 1):
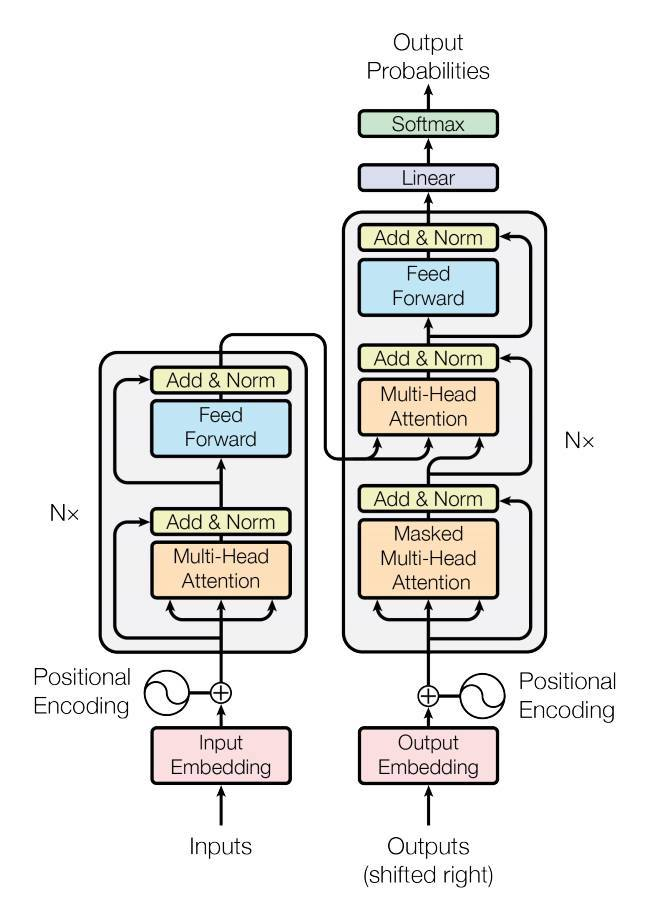
Figure 1: Transformers architecture [1]
Transformers are originally proposed for sequence transduction tasks such as machine translation. Their architecture is composed of:
- Input/Output Embedding: Input and output words are transformed to fixed-sized embeddings using a shared weights‘ matrix across the encoder and the decoder
- Positional encoding: enrich embeddings with context based on the position of a word in the sentence (distances between words), e.g. using sin and cos functions.
- Encoder block
- Multi-head attention: Applies self-attention to each word in the sentence: How relevant the i-th word is with other words in the sentence? This enriches learnt embeddings with contextual information.
Multiple heads are used to learn multiple attention vectors for each word representation. Words are projected in different learned embedding subspaces in each head. The outputs of these heads are aggregated via concatenation and projected again
- Feed-forward network: applied to each one of the attention vectors to prepare them to be fed to the decoder block
- Decoder Block
- Masked multi-head attention: same mechanism as in encoder block, however, for decoding, not all words are used in the sentence for each word. As such, it only uses previous words in the sentence. This avoids what is known as data leakage.
- Multi-head attention: encoder-decoder attention is applied at this block between learned representations of each word in the input sentence and the output sentence. This focuses on the question „How related is each word vector to others in both input and output?“
- Linear layer: another feed-forward network to expand the resulted dimension into the number of words in the target language
- Softmax layer: gets the probability distributions. The predicted word is the one corresponding to the target word with the highest probability
Instead of training a task-specific transformer model from scratch, It is most common to use pre-trained transformer architecture-based models and adapt them to down-stream tasks via fine-tuning (i.e. transfer learning). State-of-the-art pre-trained language models that are based on the original transformer architecture are BERT (the encoder), GPT (the decoder), and BART (the encoder and decoder).
Pre-training of transformer models is usually performed in a self-supervised manner for language modeling. This means that they have been trained on a large corpus of unlabeled text data, and are therefore able to extract universal language representations to be reused and adapted to various downstream supervised tasks.
What is BERT?
BERT (Bidirectional Encoder Representations from Transformers) [3] is a large language model developed by Google AI.
- Pretrained : with two unsupervised tasks: masked language modeling (i.e. prediction of randomly masking words from the input sentence) and next sentence prediction and using BooksCorpus and English Wikipedia (16GB)
- Bidirectional : deeply fuse the left and right context in the learned representation of each token.
The architecture of BERT is composed of multiple encoder layers that apply self-attention to its input and pass it to the following layer. For instance, the smallest BERT model, BERT BASE, has an architecture composed of 12 encoder layers (cf. Figure 2), 768 hidden units in its feed-forward neural network block, and 12 attention heads.
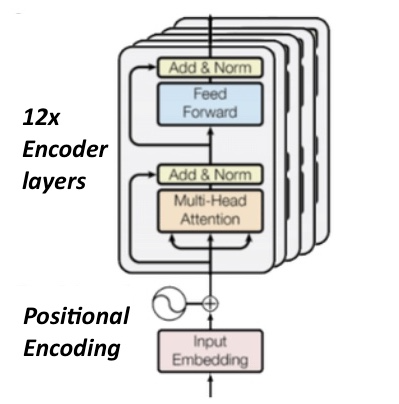
Figure 2: BERT BASE architecture [4].
Input representations
BERT takes as input sequences that are composed of sentences or pairs of sentences (<question, answer> for question-answering tasks). Input sequences are prepared before being fed to the model using WordPiece Tokenizer with a 30k vocabulary size. It works by splitting a word into several subwords (Tokens). The use of subwords instead of words significantly reduces the total vocabulary size (only 30k) and the number of potential out-of-vocabulary (OOV) tokens.
Special tokens are:
- [CLS] used as the first token of each sequence. It is introduced in the original BERT implementation to use its corresponding final hidden state for classification tasks, where only one vector that represents the entire input sequence is needed to be fed to the classifier.
- [SEP] used to separate the pair of sentences in the input sequence (e.g. question answering) or as the end token.
- [PAD] used to represent paddings in the input sentences (empty tokens). The model expects fixed-length sentences as input. A maximum length is thus fixed depending on the dataset. Shorter sentences are padded, whereas longer sentences are truncated. To explicitly differentiate between real tokens and [PAD] tokens, we use an attention mask.
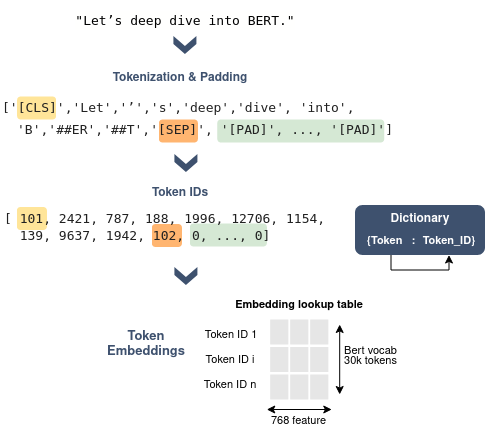
Figure 3: Example of a sentence encoding using BERT.
Each token will be then encoded by its ID which corresponds to its index in the vocabulary.
Eventually, for each token, the input embedding is the sum of the token embedding, the segmentation embedding, and the positional embedding. To get the token embedding, an embedding lookup table is used at the embedding layer (as illustrated in Figure 3 above), where rows represent all possible token IDs in the vocabulary (30k rows for instance) and columns represent the token embedding size (cf. Figure 3).
Segmentation embedding is introduced to indicate if a given token belongs to the first or second sentence. Positional embedding indicates the position of tokens in a sentence. By contrast to the original Transformer, BERT learns positional embeddings from absolute ordinal position, instead of using trigonometric functions.
Feature Extraction from Text
BERT can be used out-of-the-box (i.e. at inference) to extract machine-readable data representations from text. Once this is done, applying traditional machine learning or deep learning techniques such as classification or regression becomes a straightforward process.
To create embedding using transformers, we start by adding special tokens to the input text. This preprocessing step is required since the (transformer’s) model was trained on data that follows this organization.
In the code snippet below, we manually add the CLS and SEP tokens to respectively mark the start of a sentence and when a new sentence begins. After that, we create separate tokens by dividing a sentence into words or partial words using the tokenize method from a pre-trained BERT tokenizer. Finally, we add the PAD token to a fixed size equal to a pre-set maximum sentence length.
Code:
from transformers import BertModel, AutoTokenizer
from transformers import BertModel, AutoTokenizer
import torch
# load „bert-base-cased“ the pre-trained model
model = BertModel.from_pretrained(‚bert-base-uncased‘, output_hidden_states = False)
# load the corresponding wordtokenizer
tokenizer = AutoTokenizer.from_pretrained(„bert-base-uncased“)
# example sentence
text = „Let’s deep dive into BERT.“
# add [CLS] and [SEP] tokens
text = „[CLS]“+text.replace(‚\.‘, ‚[SEP]‘)
# get tokens from the sentence
tokens = tokenizer.tokenize(
text=text,
)
# set the maximum length of a sentence
max_length = 30
# add [PAD] tokens to shorter sentences
padded_tokens = tokens + [‚[PAD]‘ for _ in range(max_length-len(tokens))]
# get token IDs
token_ids = tokenizer.convert_tokens_to_ids(padded_tokens)
# generate the attention mask
attention_mask = [1 if token != ‚[PAD]‘ else 0 for token in padded_tokens]
# whether each token belongs to sentence A (0) or sentence B (1)
segment_ids = [0 for _ in range(len(padded_tokens))]
# convert lists to tensors
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
segment_ids = torch.tensor(segment_ids).unsqueeze(0)
To retrieve the input embeddings extracted from the token IDs:
# get input embeddings
input_embeddings = model.embeddings(token_ids, token_type_ids=segment_ids)
Two types of embeddings can be extracted from the input text.
- Token-level embeddings: these are the embeddings generated by default by the last hidden states of BERT. It consists in representing every token in a separate embedding. Token-level embeddings are used for question answering and named entity recognition.
- Sequence-level embeddings: This requires a pooling post-processing of generated token-level embeddings. We extract same-length embeddings for each sentence in the text [5]. Pooling can be performed by taking the mean of token embeddings (most used), the max, or by taking the output of the first token of each sentence (CLS token output) [6]. Sequence-level embeddings can be useful for text classification and sentiment analysis applications.
Code:
# set the model in evaluation mode
model.eval()
# get contextual embeddings
with torch.no_grad():
# output of shape <batch_size, max_length, embedding_size>
last_hidden_states = model(token_ids, attention_mask=attention_mask, token_type_ids=segment_ids)[„last_hidden_state“]
# first token embedding of shape <1, hidden_size>
first_token_embedding = last_hidden_states[:,0,:]
# pooled embedding of shape <1, hidden_size>
mean_pooled_embedding = last_hidden_states.mean(axis=1)
In this section, we presented in detail how to generate text embeddings using BERT. For demonstration reasons, have manually added special tokens to our text. However, it’s possible to automate this pre-processing step in HuggingFace transformers library by making use of encode_plus function :
# encode the sentence
encoded = tokenizer.encode_plus(
text=sentence,
add_special_tokens=True, # add [CLS] and [SEP] tokens
max_length = 30, # set the maximum length of a sentence
truncation = True, # truncate longer sentences to max_length
padding=’max_length‘, # add [PAD] tokens to shorter sentences
return_attention_mask = True, # generate the attention mask
return_tensors = ‚pt‘, # return encoding results as PyTorch tensors
)
# get the token IDs and attention mask
token_ids = encoded[‚input_ids‘]
attention_mask = encoded[‚attention_mask‘]
Fine-tuning for down-stream tasks
As mentioned earlier, BERT can be used out-of-the-box as a feature extractor to generate text embeddings. However, to achieve the best performance, it should be fine-tuned on the target dataset.
Fine-tuning is a transfer learning technique that allows data scientists to solve target problems by applying a model trained on different source tasks or datasets. In the context of NLP applications, the models used are already trained on large text corpus thus they have general language understanding, and they capture complex semantic relationships in texts. Previous research initiatives have proven that fine-tuning existing LLMs leads to better results with fewer data and in less time than training from scratch a new neural network like Transformer, CNN or BiLSTM [7].
For task-specific fine-tuning, we add a trainable fully connected layer to the architecture and only a few epochs are needed to optimize it and obtain the desired result.
Hereafter, we briefly present fine-tuning strategies for the three most common use cases: sequence classification, token classification, and question answering.
- Sequence classification: we simply add a classification layer that takes as input the sequence-level embedding and outputs the class label.
It can be used on a single text sequence (e.g. sentiment analysis and topic classification), or on a pair of text sequences (e.g. natural language inference and semantic textual similarity). The difference between the two cases is shown in Figures 4 and 5.
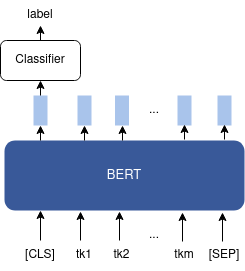
Figure 4: Fine-tuning BERT for sequence classification. As pooled sequence-level embedding, we take the embedding of the [CLS] token.
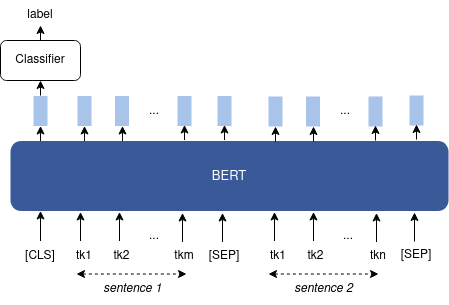
Figure 5: Fine-tuning BERT for sequence-pair classification.
- Token classification: the added classification layer takes as inputs token embeddings and outputs each token’s class label (cf. Figure 6). Typical applications of token classification are named entity resolution and part-of-speech tagging.
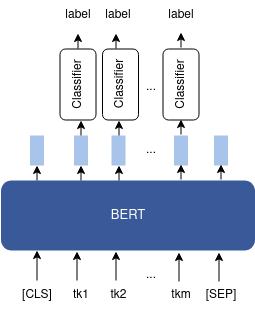
Figure 6: Fine-tuning BERT for token classification.
- Question answering: takes as input two text sequences, where the first one is the question and the second one is the passage that the question is about, its context (cf. Figure 7). The answer is a segment (text span) of this passage. The output layer will learn the probabilities of each token in the passage of being the start and the end index of the answer. The predicted answer is the one spanning between the start/end tokens with the largest start/end probabilities.
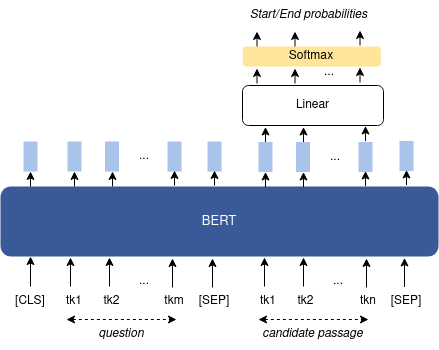
Figure 7: Fine-tuning BERT for question answering.
Conclusions
In this article, we summarized core concepts about transformers and walked through classic applications of BERT models, specifically text feature extraction, text classification, and question answering.
BERT uses the encoder part of the Transformer architecture to generate contextualized embeddings. The bidirectional pre-training allows it to capture both the left and right context of words for language understanding.
Other popular LLMs for tackling related problems are decoder-based models like GPT and encoder-decoder-based models like BART. In general, encoder-based models are used for predictive modeling tasks like classification. Decoder-based models are optimized for next-word prediction using causal/autoregressive attention. Hence, they are more adapted for text generation tasks. The third category, which combines the encoder and the decoder parts, has a more generalist approach and achieved state-of-the-art results for both kinds of applications.
The article is intended as an overview of the field and an introduction for enthusiasts to building BERT-based NLP applications. Be sure to tell us your thoughts and suggestions in the comments section below.
Thank you for reading!
Who are Asma Zgolli and Mouna Labiadh?
Asma Zgolli

Asma Zgolli (https://www.linkedin.com/in/asma-zgolli-225642a5/) is a senior machine learning engineer at Byte Commerce (https://bytecommerce.co/), a tech startup that builds innovative e-commerce solutions. She is also a data science contributor to MI4poeple (https://www.linkedin.com/company/mi4people/), a non-profit organization that fosters the utilization of Machine Intelligence (MI) for Public Good through applied research. She has a background in Big data and is passionate about building and designing scalable data solutions and solving business problems using her analytical skills.
Asma has a PhD in Big data and applied machine learning from the University of Grenoble Alpes (UGA) and is a graduate software engineer from the National Institute of Applied Sciences and Technology (INSAT). She published research articles in renewed conferences like IDEAS, MTSR, and BDA and recently started writing blogs about data and artificial intelligence (https://medium.com/@zgolliasma).
More generally, her tech interests are deep learning, NLP, computer vision, big data, data lakes, time series, graph databases, multi-store query optimization, and recommendation systems.
Mouna Labiadh

Mouna Labiadh <https://www.linkedin.com/in/mouna-labiadh-bb374268/> is a data science consultant at Aquila Data Enabler in Paris, France. Her responsibilities encompass developing data and AI-driven solutions for clients across various industries.
Mouna holds a Ph.D. in applied machine learning from the university of Lyon, a M.Sc. degree in Data Science from Grenoble INP-ENSIMAG, and a software engineering degree from INSAT Tunis. She recently started to blog about her expertise and skills <https://medium.com/@mouna.labiadh>. Her main interests include deep learning, time series, transfer learning, NLP and MLOps.
References
[1] Vaswani, Ashish, et al. „Attention is all you need.“ Advances in neural information processing systems 30 (2017).
[2] Cho, Kyunghyun, et al. „Learning phrase representations using RNN encoder-decoder for statistical machine translation.“ arXiv preprint arXiv:1406.1078 (2014).
[3] Devlin, Jacob, et al. „Bert: Pre-training of deep bidirectional transformers for language understanding.“ arXiv preprint arXiv:1810.04805 (2018).
[4] Khalid, Usama & Beg, Mirza & Arshad, Muhammad. RUBERT: A Bilingual Roman Urdu BERT Using Cross Lingual Transfer Learning. (2021).
[5] Choi, Hyunjin, et al. „Evaluation of bert and albert sentence embedding performance on downstream nlp tasks.“ 2020 25th International conference on pattern recognition (ICPR). IEEE, 2021.
[6] Reimers, Nils, and Iryna Gurevych. „Sentence-bert: Sentence embeddings using siamese bert-networks.“ arXiv preprint arXiv:1908.10084 (2019).
[7] Chris McCormick and Nick Ryan. (2019, July 22). BERT Fine-Tuning Tutorial with PyTorch. Retrieved from“http://www.mccormickml.com„
Good Reads
- How Does Attention Work in Encoder-Decoder Recurrent Neural Networks – MachineLearningMastery.com
- Hugging Face NLP Course
- The Illustrated Transformer – Jay Alammar
- Multi-head attention mechanism: „queries“, „keys“, and „values,“ over and over again – Data Science Blog
- Fine-tuning with custom datasets — transformers 3.2.0 documentation
How do transformers differ from recurrent neural networks (RNNs) in terms of modeling sequences and training process parallelization? How do transformers handle the encoding of word order in a sequence?